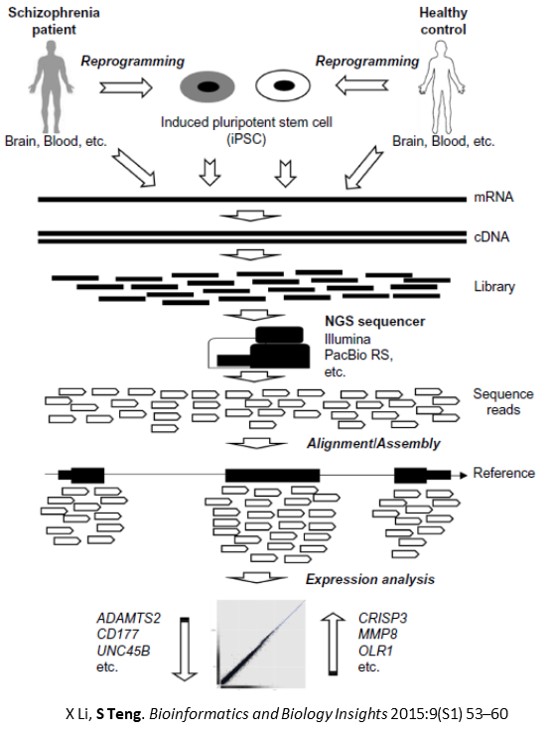
NEXT-GENERATION SEQUENCING (NGS)
NGS technologies make the sequencing much faster and cheaper, which have revolutionized genetic research and accelerated precision medicine. We are using whole genome sequencing and targeted sequencing to identify the sequence variants that contribute to major psychiatric disorders including schizophrenia, bipolar disorder and major depressive disorder. We are applying RNA sequencing to study gene expression changes in model organisms. In addition, we are developing bioinformatics tools and databases to analyze NGS data for mental illness and cancer research.
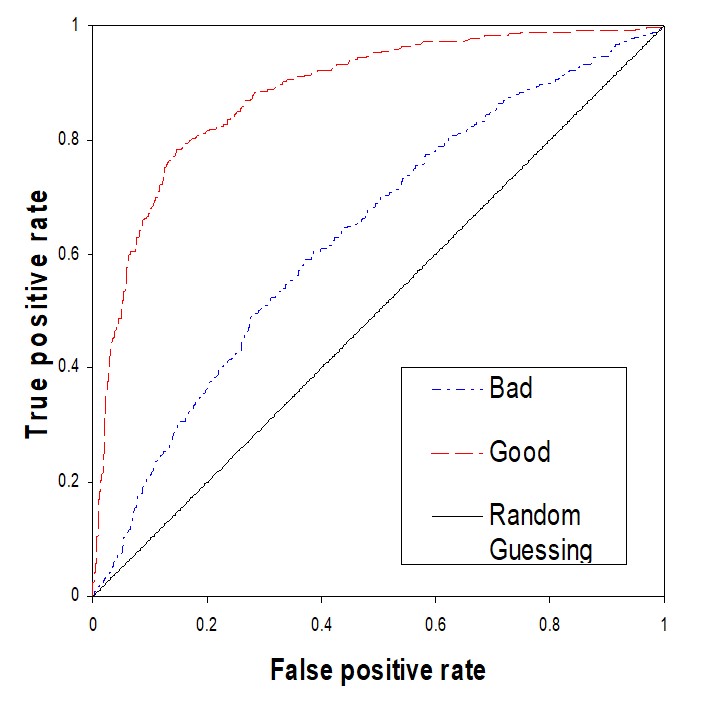
MACHINE LEARNING
Machine learning can recognize complex and hidden pattern from massive data sets, and it is particularly appealing for biological knowledge discovery in big data. We are developing new machine learning methods to analyze NGS data, disease-causing mutations and protein post-translational modifications.
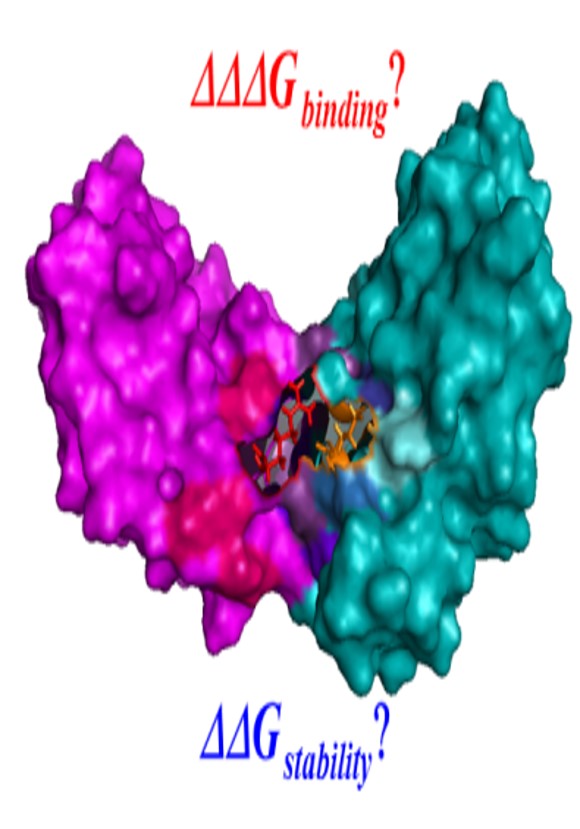
PROTEIN STRUCTURE MODELING
Structure modeling provides an efficient and accurate way to investigate the functional effects of coding sequence variants by mapping them on the corresponding structure models. We are using homology modeling and energy calculation approaches to estimate the effects of missense variants on protein stability and protein-protein interactions, and investigate the roles of the mutations in complex diseases such as obesity, cancers and psychiatric disorders.

Research Support
NSF Excellence in Research (#2000296)
NSF Harnessing the Data Revolution: Data Science Corps (#1924092)
NSF Targeted Infusion Project (#2011933)
DoD Center of Excellence in Artificial Intelligence & Machine Learning
RCMI Investigator Development Core